{kind=link}
{kind=link}
{kind=link}
Jak se to vezme :)
Za zaklad povazuju spojovani tabulek, JOINy, operace s datumem a casem, GROUP BY.
Pokrocile jsou podle mne dotazy s UNION, HAVING, atd...
ale je to asi dost subjektivni..
Dnes se zaměřím na další méně známou funkcionalitu SQL a to podmínku HAVING.
HAVING je velmi podobná podmínce WHERE. Rozdíl je v tom, že podmínka WHERE omezuje ještě neseskupené záznamy a podmínka HAVING omezuje seskupené záznamy.
Malá odbočka pro ty kdo nevědí, co znamená seskupování (přeskočit): Seskupení záznamů znamená, že shrneme informace několika záznamů do jednoho záznamu. K tomuto používáme GROUP BY, za kterým uvedeme název sloupce, podle kterého se mají záznamy seskupit (všechny záznamy, které mají stejnou hodnotu tohoto sloupce, se sloučí do jednoho záznamu).
Při použití GROUP BY musíme ale dodržet podstatné omezení: Do seznamu výstupních sloupců můžeme uvést pouze ty sloupce, u kterých jsou v celé skupině konstantní hodnoty, a nebo agregační funkce. Agregační funkce jsou funkce, které mají na vstupu více hodnot, ale na výstupu jen jednu. Dobrým příkladem je COUNT() - vrátí počet sloučených záznamů, MAX() - vrátí nejvyšší hodnotu sloupce, AVG() - vrátí průměrnou hodnotu sloupce, SUM() - vrátí součet všech hodnot ve sloupci.
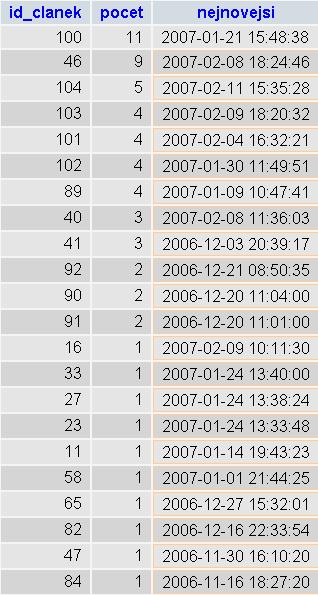
Využití GROUP BY je opravdu široké. Jedním dotazem například mohu zjistit, kolik má komentářů každý článek a kdy byl přidán poslední komentář. Pro názornost výsledek ještě omezím na komentáře staré maximálně 3 měsíce a setřídím jej podle počtu komentářů a jejich data.
SELECT `id_clanek`,COUNT(*) AS `pocet`, MAX(`datum`) AS `nejnovejsi` FROM `nors_komentar` WHERE TO_DAYS( NOW() )-TO_DAYS(`datum`) < 90 GROUP BY `id_clanek` ORDER BY `pocet` DESC,`nejnovejsi` DESCNa výsledek se můžete podívat zde.
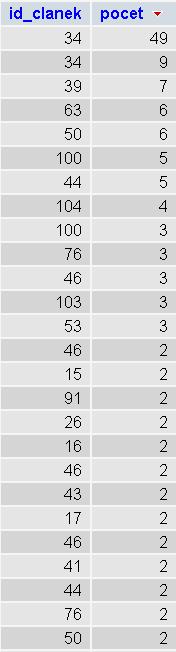
Jak vidíte, může nám GROUP BY často ušetřit dost práce. Velice zajímavé také je, že můžeme za GROUP BY uvést více sloupců nebo dokonce i výraz. Jenoduše například zjistíme kolik komentářů bylo jednotlivým článkům přidáno během jednoho dne.
SELECT `id_clanek`,COUNT(*) AS `pocet` FROM `nors_komentar` GROUP BY `id_clanek`, TO_DAYS(`datum`) ORDER BY `pocet` DESCVýsledek. Jak vidíte záznamy jsou opravdu seskupené nejen podle ID článku, ale i podle dne publikace.
Nyní zpět k HAVING. Jak už jsem řekl, WHERE omezuje záznamy ještě před seskupením a HAVING až po seskupení. Další rozdíl je, že podmínka HAVING se musí týkat sloupce, který má konstantí hodnotu a nebo agregační funkce.
Můžeme tedy například náš dotaz s počtem komentářů článku omezit pouze na ty články, které mají více než 5 komentářů.
SELECT `id_clanek`,COUNT(*) AS `pocet`, MAX(`datum`) AS `nejnovejsi` FROM `nors_komentar` WHERE TO_DAYS( NOW() )-TO_DAYS(`datum`) < 90 GROUP BY `id_clanek` HAVING `pocet` > 5 ORDER BY `pocet` DESC,`nejnovejsi` DESCVýsledek je dost nemilý:)
Podmínka za HAVING se ale nemusí (stejně jako u WHERE) týkat výstupních sloupců.
Nyní jeden hezký příklad z praxe:
Mějme portál s ubytováním, na kterém je i vyhledávání podle parametrů. U některých vlastností chceme, aby je mělo ubytovací zařízení všechny zárověň. Například, aby na pokoji byla televize, satelit i lednička.
Máme tabulku hotel, tabulku pokoj_vybaveni a spojovací tabulku hotel_pokoj_vybaveni.
 Spojovací tabulka je zde proto, že mezi tabulkami hotel a pokoj_vybaveni je vztah M:N. Jeden záznam z pokoj_vybaveni může mít na sebe navázáno několik hotelů a naopak.
Spojovací tabulka je zde proto, že mezi tabulkami hotel a pokoj_vybaveni je vztah M:N. Jeden záznam z pokoj_vybaveni může mít na sebe navázáno několik hotelů a naopak.
Chceme tedy zjistit, který záznam z tabulky hotel je navázaný na několik určitých záznamů z tabulky pokoj_vybaveni zároveň. Mohli bychom zjistit, které hotely jsou navázané na jeden záznam, pak které jsou navázané na druhý záznam a oba výsledky porovnat. To je ale mrhání zdroji.
WHERE nám tu nepomůže, ten se může vždy postarat jen o jednu vazbu. My ale potřebujeme kontrolovat více vazeb najednou.
A právě teď se nám hodí HAVING.
SELECT h.* FROM hotel AS h, hotel_pokoj_vybaveni AS hpv WHERE (h.id_hotel=hpv.id_hotel) AND ((hpv.id_pokoj_vybaveni = '1') OR (hpv.id_pokoj_vybaveni = '3') OR (hpv.id_pokoj_vybaveni = '13') ) GROUP BY h.id_hotel HAVING (count(distinct hpv.id_pokoj_vybaveni) >= 3)
Nejprve spojíme tabulku hotel s tabulkou hotel_pokoj_vybaveni. Tabulku hotel_pokoj již připojovat nemusíme, protože známe ID. To provedeme podmínkou (h.id_hotel=hpv.id_hotel). Kdybychom tak neučinili a přidali do výstupních sloupců sloupce z hotel_pokoj_vybaveni, vznikl by nám kartézský součin těchto tabulek.
Nyní potřebujeme dostat všechny hotely, které mají alespoň jednu chtěnou vlastnost (televizi, satelit nebo ledničku). Proto volíme podmínku ((hpv.id_pokoj_vybaveni = '1') OR (hpv.id_pokoj_vybaveni = '3') OR (hpv.id_pokoj_vybaveni = '13') ). Nyní máme tedy seznam všech hotelů (které se mohou opakovat), které splňují alespoň jednu podmínku. Teď přijde to hlavní. Pomocí GROUP BY je seskupíme pomocí id_hotelu. Tím jsme tedy už dostal seznam hotelů, kde je každý hotel jen jednou. Seznam ale obsahuje i hotely, které nesplňují všechny tři podmínky zároveň. Proto je na konci podmínka HAVING (count(distinct hpv.id_pokoj_vybaveni) >= 3). Tedy přeloženo do lidštiny: Počet různých ID_pokoj_vybaveni u skupiny musí být větší nebo roven třem.
Při seskupování záznamů se tedy výsledek omezí na pouze ty seskupené záznamy, kde záznamy skupiny před seskupením obsahovaly alespoň 3 různé hodnoty sloupce id_pokoj_vybaveni.
Není to krásné? :)
Jak se to vezme :)
Za zaklad povazuju spojovani tabulek, JOINy, operace s datumem a casem, GROUP BY.
Pokrocile jsou podle mne dotazy s UNION, HAVING, atd...
ale je to asi dost subjektivni..
#3 Odeus: Je ti jedno, že tvá poznámka je úplně mimo? Standa neřekl, že to tu nemá bejt. Ale, že by tohle hledal spíše v kategorii začátečníky.
a na kazdem foru se najde jouda, co se musi hadat
#4 Taco: hodnota tveho tvrzeni je asi tak stejne relevantni jako odeusova..
Skvěle vysvětleno, díky, zase jsem o něco chytřejší :)

Píše Daniel Milde aka Dundee
Powered by NORS 4.3.9©2007-2015 Daniel Milde aka Dundee |
 |
| |
|
Využíváme soubory cookie. Používáním webu vyjadřujete souhlas.
Jen jsem to prolitnul, asi dobre vysvetlene, jen nechapu proc je popis takovehleho zakladu zarazeny do SQL pro pokrocile. Tohle je pro zacatecniky :-)