Velkou výhodou skriptovacího jazyka Python je ukládání mezikódu jednou zparsovaných skriptů na disk, což velmi zkracuje čas potřebný pro znovuspuštění aplikace. Obdobnou funcionalitu můžeme zprovoznit i pro PHP, stačí k tomu nainstalovat patřičné rozšíření.
Minislovníček
- PHP interpret - Aplikace umožňující spuštění programu přímo ze zdrojového kódu bez potřeby zdrojáky v předstihu kompilovat.
- Kompilátor PHP - Součást interpretu. Jedná se o parser, který vytvoří mezikód, jenž je následně vykonán.
- PHP mezikód - jazyk symbolických adres (assembler), do kterého jsou před vykonáním překládány všechny skripty. Každý skript projde nejprve lexikální analýzou (převedením na tokeny) a syntaktickou analýzou s překladem.
Definice pojmů jsou velmi zjednodušené a jsou zasazeny pouze do kontextu jazyka PHP - jedná se tedy o PHP interpret, kompilátor PHP a PHP mezikód. Jinak obecně interpret samozřejmě nemusí vykonávat pouze zdrojové kódy, ale také mezikód nebo bytecode.
Motivace
Motivací nám bude především to, že u mnoha aplikací zabere více času zparsování všech načítaných skriptů než samotné provedení mezikódu. Zejména pokud je naše aplikace postavená nad frameworkem Zend, je použití cache kompilátoru téměř nutností.
APC
Projektů, které se zabývají znovuvyužitím mezikódu, je několik. My se zaměříme na ten asi nejznámější, vyvíjený samotnými vývojáři PHP a to je projekt APC.
Rozdíly oproti Pythonu
APC narozdíl od Pythonu neukládá mezikód do souborů na disk, ale do operační paměti. To má samozřejmě své výhody i nevýhody. Výhodou je, že spuštění aplikace je ještě rychlejší a je potřeba méně přístupů na disk. Nevýhodou pak je vyšší paměťová náročnost a dočasnost uložení (při restartu Apache o celou cache přijdeme).
Požadavky pro běh interpretu
APC je rozšíření PHP, a proto, aby správně fungovalo, je potřeba aby interpret PHP stále běžel. Pokud spustíme PHP jako CGI skript, bude nám APC na nic, protože se při každém požadavku bude interpret spouštět odznovu a cache APC se po každém požadavku smaže.
Při běhu PHP jako modulu Apache je situace lepší - o celou cache přijdeme jen při restartu Apache. Jelikož interpret PHP neběží pouze v jedné instanci, ale každý child proces Apache má svojí vlastní (těchto procesů může být i desítky - podle zatížení serveru), musejí jednotlivé instance sdílet cache mezi sebou. To může občas vést k tomu, že různí potomci Apache budou mít různou cache.
Při běhu PHP jako FastCGI je situace obdobná jako u modulu.
Nároky na paměť
V základním nastavení si APC alokuje pouhých 30MB pro celý server. To s rezervou stačí na běh tří aplikací rozsahu Magento shopu, takže pro privátní server s jednou doménou je toto nastavení naprosto dostačující.
Instalace
Instalace je na Ubuntu opět velmi jednoduchá.
sudo apt-get install php-apc
sudo apache2ctl graceful
Při instalaci je vytvořen konfigurační soubor /etc/php5/cgi/conf.d/apc.ini, kde můžeme měnit nastavení.
Testování
Sestava: Ubuntu 8.10, Apache 2.2.9, PHP 5.2.6 jako FastCGI, Intel Pentium D 805, 2048 DDR2 RAM. Testováno nástrojem Apache Bench.
| aplikace | RPS s APC | RPS bez APC | nárůst výkonu |
|---|
| Magento e-shop (209 vkládaných souborů) | 5,26 | 2,98 | 176% |
| Nette Fifteen (56 vkládaných souborů) | 121 | 40 | 302% |
| aplikace s databází (37 vkládaných souborů) | 86,43 | 49,23 | 175% |
| aplikace bez databáze (32 vkládaných souborů) | 164 | 74 | 221% |
| menší aplikace bez databáze (9 vkládaných souborů) | 426 | 177 | 240% |
Z výsledků testů je zřejmé, že nasazení APC se opravdu vyplatí. Narůst výkonu minimálně o 150% může mnoha webům velmi odlehčit.
Odkazy
dokumentace APC
download APC
Utilitka
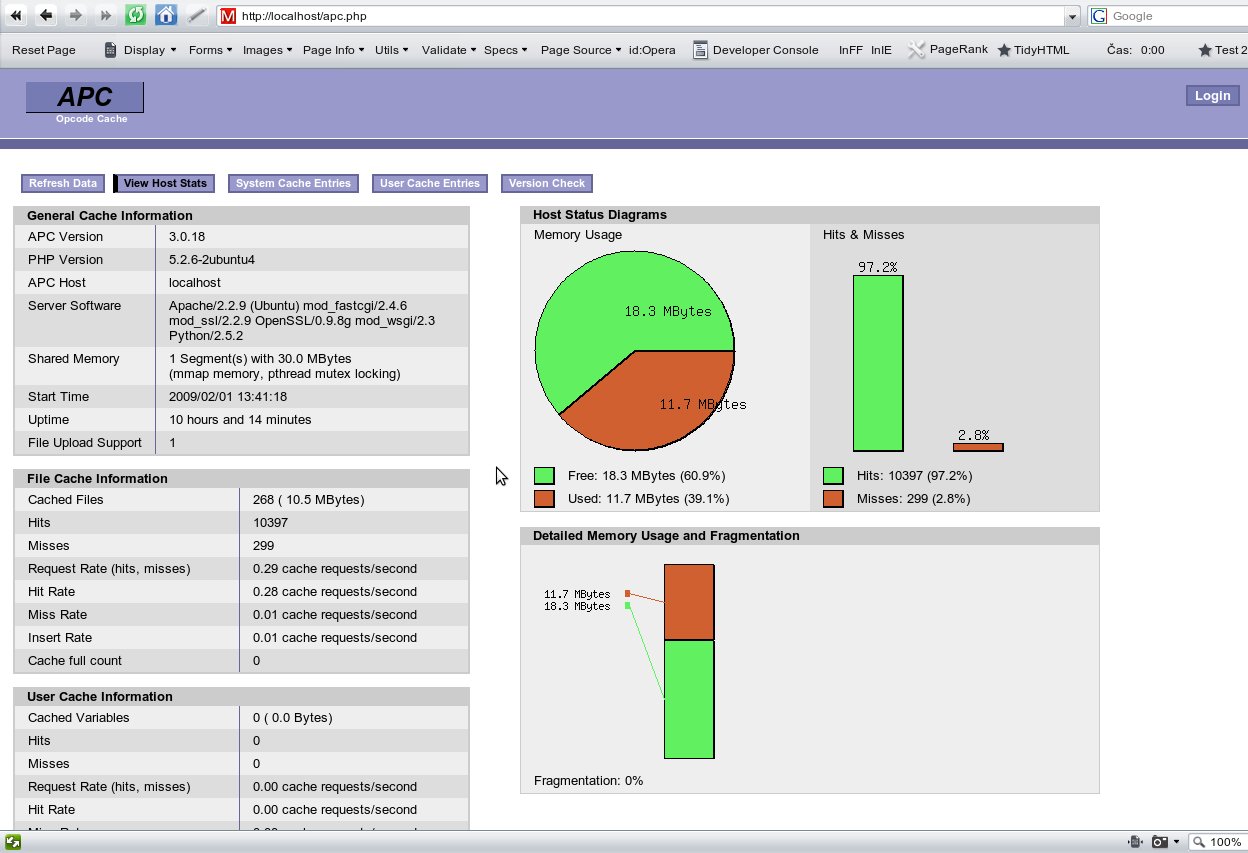
APC obsahuje moc pěkný skript apc.php, který umí zobrazit aktuální vytížení paměti, úspěšnost cache a další. Utilitka bohužel není obsažena v balíku z repozitáře. Je proto potřeba stáhnout z odkazu výše celé APC a skript si z něj zkopírovat.



Rozvinu své výhrady, co jsem psal po twitteru:
Jazyky se v zásadě dělily na jazyky interpretované a jazyky kompilované. U kompilovaných jazyků (typicky C nebo Pascal) existoval program, který se nazýval "kompilátor" (nebo kompiler). Jeho úkolem bylo přeložit zdrojový kód ve vyšším jazyce na kód v jazyce nižším, typicky na strojový kód ("nativní"). Takto přeložený kód pak fungoval bez dalších nutných věcí (a hlavně bez kompileru).
U interpretovaných jazyků (typicky BASIC) existoval místo kompileru tzv. "interpret", což byl program, který prováděl přímo příkazy vyššího jazyka bez překladu do jazyka nižšího - což říkám zjednodušeně, ale dalo by se to připodobnit k "virtuálnímu stroji", který přímo vykonává příkazy zapsané ve vyšším jazyku.
Kompilované jazyky byly rychlejší, interpretované zase měly možnost interaktivní práce a (teoreticky) běhu všude možně kde existoval interpret bez nutnosti překládat do native kódu.
Určitým hybridem byly jazyky s p-kódem. U takových přeložil kompilátor zdrojový kód do "mezikódu" (p-kódu) a ten byl pak interpretován malou "runtime" knihovnou. Výhodou byla přenositelnost (opět spíš teoretická) onoho p-kódu mezi platformami.
Tak bylo. Dnes je trochu jinak, dnes se původně ostrá hrana smyla. Dnes existují i u "interpretovaných" jazyků např. překladače do pseudokódu (tuším že třeba Python to dělá přesně tak), naopak p-kód leckdy není čistě interpretován, ale je překladačem JIT (Just-In-Time) přeložen do nativního kódu před svým prvním použitím...
Mno. A assembler či "jazyk symbolických adres"? Mikroprocesor pracuje na "své" úrovni s instrukčními kódy. Např. u Z80 znamenal kód 0x00 "nedělej nic", kód 0xC3 "přejdi na určenou adresu" nebo 0x21 "naplň registry H a L číslem". A protože by si takové kódy pamatovali jen drsní core programátoři, tak byly nahrazeny (kvůli lidem) tzv. "mnemotechnickým zápisem" v "jazyce symbolických adres". Takže místo 00 jsme psali NOP (No OPeration), JP (JumP) či LD HL,1234 (LoaD). A navíc si nikdo nemusel pamatovat, že rutina pro tisk je na adrese 0x2DC, ale napsalo se "CALL TISK" - tedy ty adresy nebyly absolutní, ale symbolické. No a assembler pak tenhle zápis vzal, mnemotechnické označení přeložil na jejich kódy, spočítal, jaká fyzická adresa odpovídá jaké symbolické, a dal to všechno dohromady. (Víceméně. Ještě tam občas býval např. linker, který to spojil s knihovnami).
Takže asi takový je vztah mezi interpretem, kompilerem, mezikódem, assemblerem a jazykem symbolických adres.